
Munich/Montreal
Blog

Technical Deep-Dive: Achieving 2.9x Speedup for MiniGPT on the AMD Radeon™ PRO V710 GPU
In our recent benchmarking of AI inference workloads on Azure’s cloud infrastructure, the MiniGPT Block demonstrated the most significant performance leap when using Yasp’s agentic compiler. We observed a 2.91x speedup over standard toolchains (torch.compile) on the AMD Radeon PRO V710 GPU.
Below is a detailed technical breakdown of exactly how yasp.compile achieves this high-performance execution on AMD hardware.
Executive Summary: How We Did It
1. Kernel fusion — Many separate PyTorch ops in the reference model (e.g., view → transpose → clone → softmax → masked_fill) are fused into a few custom kernels. This means tensors are processed in registers instead of repeatedly written to and read from GPU memory.
2. FP16 computation instead of FP32 — Most heavy operations (QKV projections, attention, MLP) run in FP16, which halves memory bandwidth usage. The final results are still within our accuracy goals, atol=1e-3, rtol=1e-8.
3. Much less global memory movement — The reference implementation performs multiple full passes over very large tensors (especially the attention matrix). The optimized kernels read data once, compute everything, and write once, cutting several GB of memory traffic. This is mainly achieved by the kernel fusions.
4. Vectorized loads and GPU-friendly kernels — The optimized kernels use vectorized memory access (float4, half2) and wavefront-level reductions, improving GPU utilization and memory bandwidth.
Kernel Fusion
Instead of dispatching dozens of small PyTorch ops that each launch a separate GPU kernel, the optimized model collapses entire computation chains into single custom kernels. The clearest example is the QKV split: the reference runs split → view → transpose → clone as four separate operations, each materializing a new tensor in HBM. The optimized version does all of this in one kernel that reads the QKV tensor exactly once and writes Q, K^T, and V directly into their final layouts:
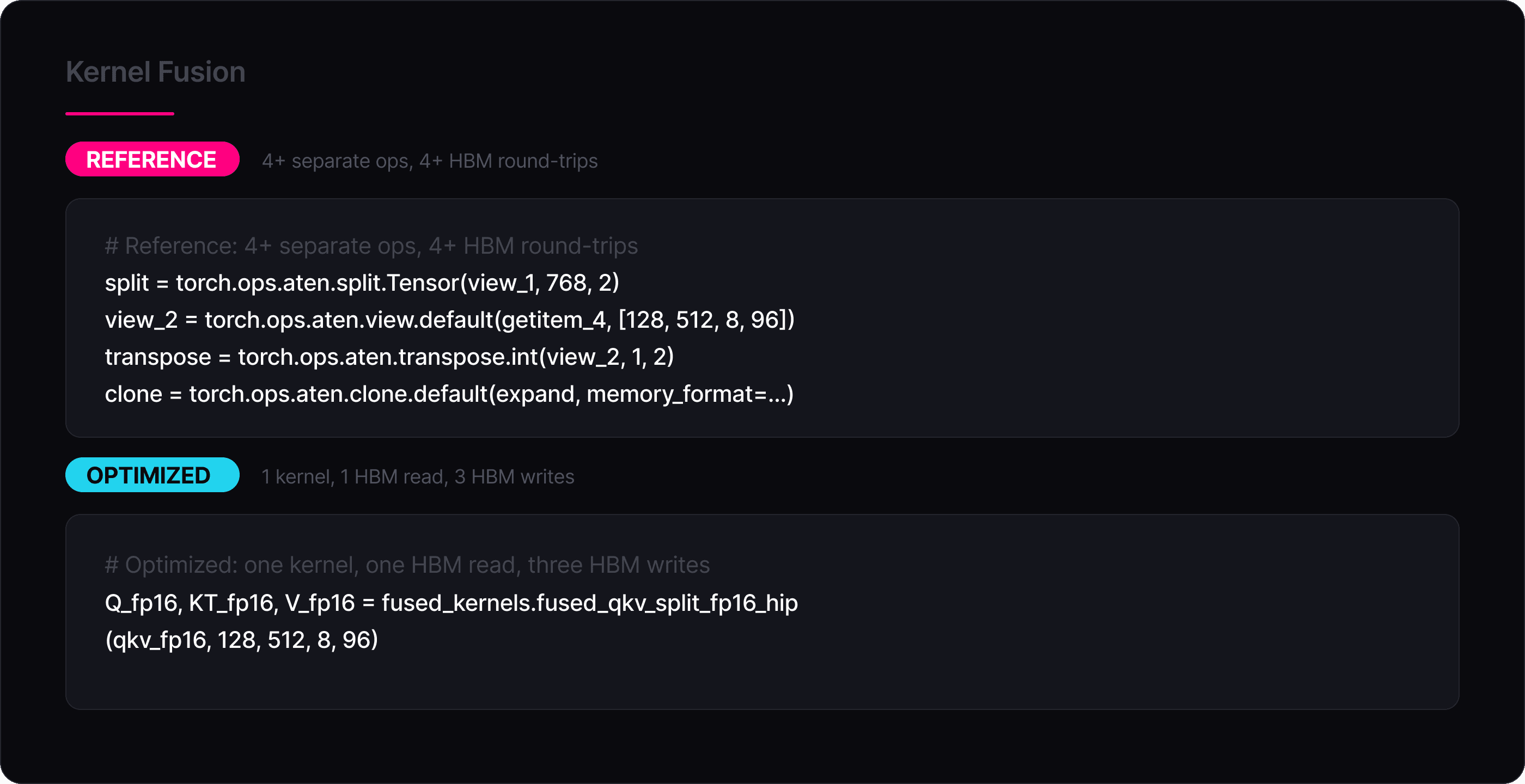
The same principle applies to the softmax (which fuses mul + masked_fill + softmax into one pass) and the residual additions (which fuse fp16→fp32 cast + add into one pass). Fewer kernel launches also means less HIP/CUDA runtime overhead and fewer global synchronization points between ops.
FP16 Computation Instead of FP32
Since the three GEMMs (QKV projection 768→2304, output projection 768→768, FFN 768→3072 and 3072→768) dominate the compute budget of a transformer block, running them in FP16 is a big source of speedup. The optimized kernel explicitly casts weights and activations to FP16 before each addmm:
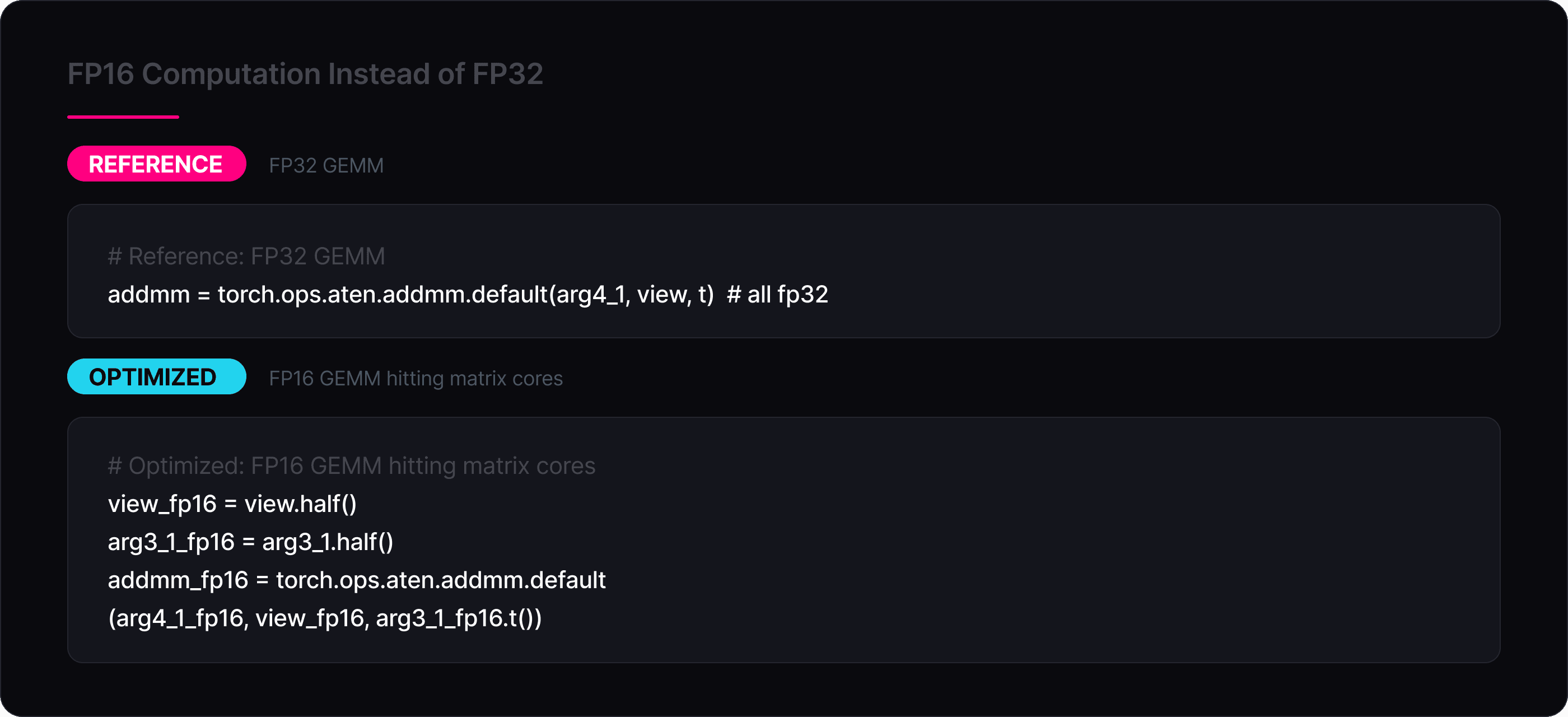
The same applies to the BMM pair inside attention and the GELU activation, which is computed in FP32 internally for numerical stability but takes FP16 input and produces FP16 output via the custom gelu_fp16_hip kernel. The FP32 precision is preserved where it matters (layer norm, residual accumulation) while the bandwidth-heavy and compute-heavy ops benefit from the smaller format.
Vectorized Loads and GPU-Friendly Kernels
AMD GPUs achieve peak memory bandwidth only when threads issue wide, coalesced memory transactions. The optimized kernels use float4 (128-bit) and __half2 (32-bit) vectorized accesses throughout, ensuring each memory transaction moves the maximum amount of data per instruction. For example, the residual add kernel reads and writes 4 floats per thread per iteration:
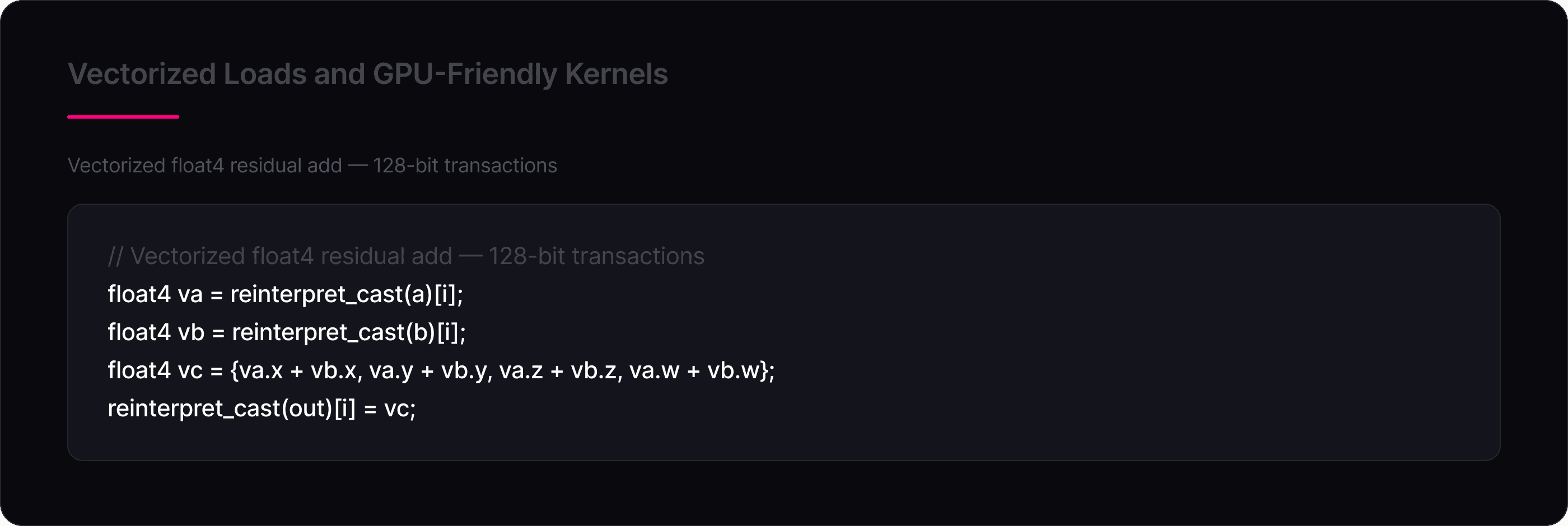
The GELU kernel similarly processes two FP16 values per thread using __half2, and the QKV split processes 4 FP16 elements at a time using pairs of __half2 loads. The softmax kernel additionally uses __shfl_down_sync for wavefront-level reductions, which communicate values through registers without touching shared memory at all for the first reduction stage. All of these patterns align with how AMD’s memory subsystem and wavefront execution model achieve peak efficiency: wide coalesced accesses, minimal shared memory contention, and register-level data reuse wherever possible.
About AMD
AMD drives innovation in high-performance and AI computing to solve the world’s most important challenges. Today, AMD technology powers billions of experiences across cloud and AI infrastructure, embedded systems, AI PCs and gaming. With a broad portfolio of AI-optimized CPUs, GPUs, networking and software, AMD delivers full-stack AI solutions that provide the performance and scalability needed for a new era of intelligent computing. Learn more at www.amd.com.
About yasp
Yasp is a German-Canadian deeptech startup focused on accelerating and simplifying the development of artificial intelligence. The company created the Agentic AI Compiler, an innovative tool that automatically optimizes AI models for any target hardware using just a single API call. By eliminating the need for manual tuning and preventing hardware vendor lock-in, Yasp helps developers deploy high-performance AI faster and more cost-effectively.