
Munich/Montreal
Blog

The Challenge
The performance of any AI model on a given GPU is ultimately dictated by the quality of the operation set available in the compiler. The better those operations map to the hardware’s execution units and memory hierarchy, the better the results. Traditional compiler search strategies, exhaustive or heuristic-based, don’t resolve to the best possible kernels. They explore a limited subset of the optimization space and settle for “good enough.”
An agentic AI compiler changes this. Instead of following fixed search patterns, it investigates different optimization scenarios autonomously and finds the best kernel implementation for that specific GPU targeting that specific model.
To demonstrate this, we picked three models with distinct computational profiles and ran them through yasp.compile, our agentic compiler, targeting the Azure NVads V710 PRO virtual machine — an AMD GPU available on Azure:
RegNet — a convolutional architecture with regular structure
DeepSeekV3 MLA — multi-latent attention, representative of modern LLM attention mechanisms
MiniGPT Block — a full transformer block with QKV projections, attention, and FFN layers
The following sections describe the results and how we achieved them.
The Solution
yasp.compile takes standard PyTorch models and automatically generates highly optimized HIP kernels specifically tuned for AMD hardware — no manual code rewrites, no exhaustive heuristic tuning.
Instead of relying on generic reference runtimes, yasp.compile analyzes the computation graph of a model and produces fused, vectorized, precision-aware kernels tailored to the target GPU’s memory subsystem and execution model. For the AMD Radeon PRO V710 GPU, this means:
Kernel fusion that collapses chains of small PyTorch ops into single GPU kernels, eliminating redundant HBM round-trips
Precision-aware computation that runs bandwidth-heavy ops in FP16 while preserving FP32 where numerical stability demands it
Vectorized memory access patterns (float4, __half2) aligned to how AMD GPUs actually achieve peak memory bandwidth
Wavefront-level reductions that keep data in registers instead of bouncing through shared memory
From a developer’s perspective, the workflow is straightforward: point yasp.compile at a standard PyTorch model, specify the target hardware, and deploy. The optimized kernels are generated under the hood. No vendor-specific code changes are required in the model itself.
Deployment on Azure
The Azure NVads V710 PRO virtual machines provide direct access to AMD GPU compute in Azure’s cloud infrastructure. For teams already running inference workloads on Azure, switching from an NVIDIA A10 GPU-based VM to an AMD Radeon PRO V710 GPU-based VM is a configuration change, and with yasp.compile handling the kernel optimization, the model code stays identical.
This is particularly relevant for organizations scaling inference across fleets of cloud VMs, where even small per-inference cost differences compound into significant savings at volume.
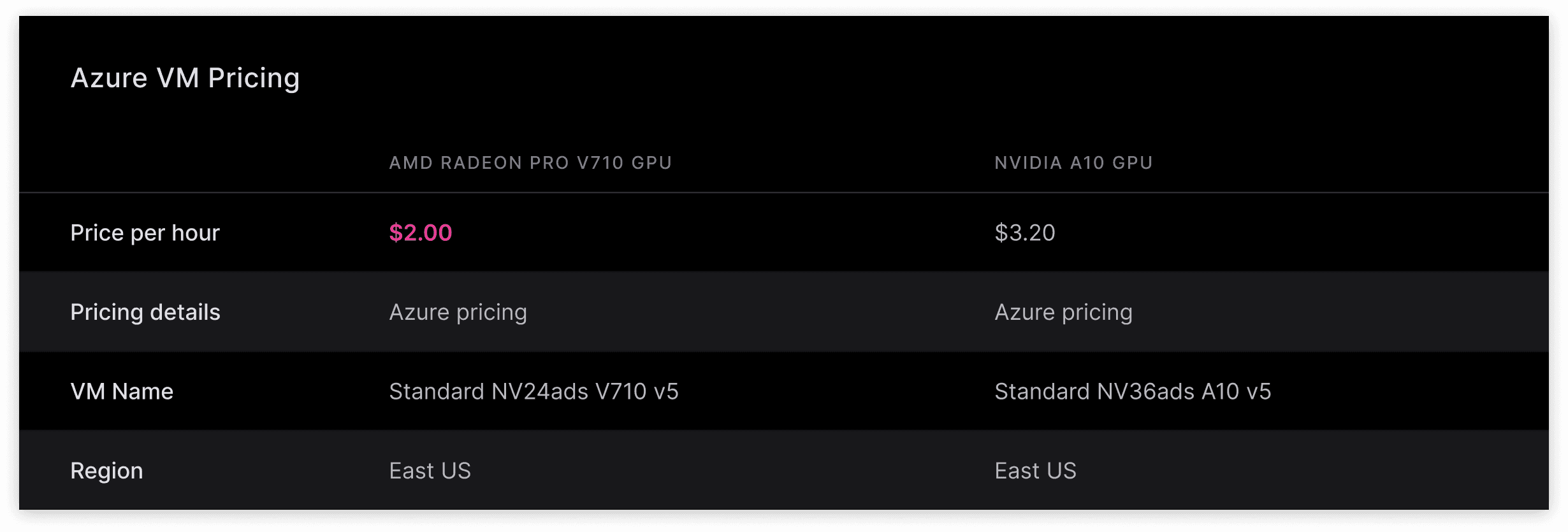
Benchmark Results
We benchmarked three models across two configurations:
yasp.compile on Azure NVads V710 PRO virtual machine ($2.00/hr)
torch.compile on Azure NVads A10 virtual machine ($3.20/hr)
The comparison targets what each hardware platform delivers when paired with its best practical toolchain. torch.compile is the standard optimization path most teams use on NVIDIA hardware; yasp.compile is what unlocks the full potential of the AMD Radeon PRO V710 GPU.

Runtime Breakdown
The raw runtime numbers tell the full story. On the AMD Radeon PRO V710 GPU, yasp.compile delivers substantial speedups over both the reference PyTorch runtime and torch.compile:

For comparison, the torch.compile runtimes on the Nvidia A10 GPU:

A key observation: on raw runtime alone, the Nvidia A10 GPU with torch.compile is faster than the AMD Radeon PRO V710 GPU with yasp.compile for RegNet and DeepSeekV3 MLA. But the AMD Radeon PRO V710 GPU’s significantly lower hourly cost ($2.00 vs $3.20) more than compensates, resulting in lower cost per inference across all three models. On MiniGPT Block, the AMD Radeon PRO V710 GPU with yasp.compile is faster in both runtime and cost.
About AMD
AMD drives innovation in high-performance and AI computing to solve the world’s most important challenges. Today, AMD technology powers billions of experiences across cloud and AI infrastructure, embedded systems, AI PCs and gaming. With a broad portfolio of AI-optimized CPUs, GPUs, networking and software, AMD delivers full-stack AI solutions that provide the performance and scalability needed for a new era of intelligent computing. Learn more at www.amd.com.
About yasp
Yasp is a German-Canadian deeptech startup focused on accelerating and simplifying the development of artificial intelligence. The company created the Agentic AI Compiler, an innovative tool that automatically optimizes AI models for any target hardware using just a single API call. By eliminating the need for manual tuning and preventing hardware vendor lock-in, Yasp helps developers deploy high-performance AI faster and more cost-effectively.