
Munich / Montreal
Nov 5, 2025
Blog

Deep learning has revolutionized whole industries, but the process of training these powerful models comes with a cost: time and computational resources. Especially the backward pass, which handles gradient calculations for every parameter, can be a major bottleneck. In fact, efficient GPU kernels are crucial for both forward and backward propagation. That’s where yasp comes in – and to be clear: yasp is not just another AI code generator. We’ve developed something new: an LLM agent that automatically generates optimized kernels, no matter your hardware. In an experiment, we just showcased the power of the yasp Agentic AI Compiler on CUDA.
Historically, hand-coding the required kernels has been a slow and complex task, simply unable to keep pace with the rapid advancements in AI research. Imagine the meticulous work involved: every line of code must be perfectly optimized for specific GPU architectures, memory access patterns, and intricate parallel processing.
This isn’t just about writing functional code; it’s about squeezing every ounce of performance out of powerful hardware. The sheer volume of new models and techniques emerging in deep learning means that relying on hand-tuned kernels is like trying to catch a bullet train on a bicycle: it’s simply unsustainable for the pace of modern AI development.
How yasp’s LLM agent supercharges kernel generation
Our LLM agent takes a structured, iterative approach to automatically generate training-ready GPU kernels. By equipping the agent with relevant, context-aware information, we ensure each kernel is tailored for optimal results. Careful prompt engineering ensures that the generated kernels are vectorized, memory-efficient, and correctly implement both forward and backward passes.
Every candidate kernel goes through a rigorous evaluation loop:
Compilation: First, it’s compiled to guarantee syntactic correctness.
Numerical testing: Next, we test its numerical accuracy against reference outputs and gradients from PyTorch.
Refinement: If any issues arise, this feedback, along with relevant profiling information, is fed back into the LLM agent. This allows our agent to regenerate and refine the kernel until it meets all our stringent correctness and performance requirements.
A look at the performance: yasp vs. the rest
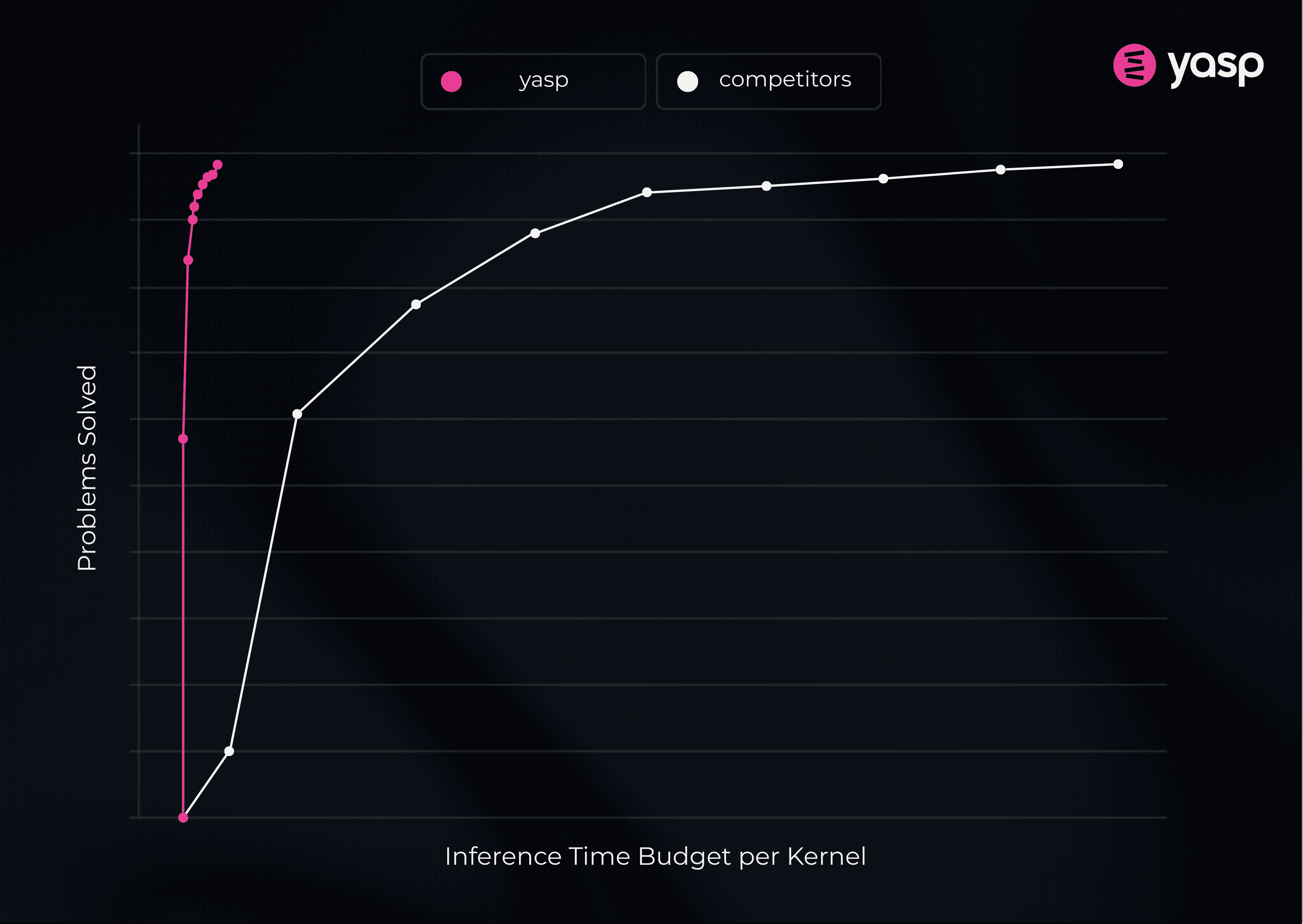
We wanted to truly put the yasp LLM agent to a test. So, we used KernelBench Level 1, a benchmark featuring 100 common operators found in real-world models, including convolutions, loss functions, layer normalizations, and activation functions.
The results are pretty compelling:
Forward pass speed: yasp’s approach achieves a 98% correctness rate for forward pass kernels in just 0.72 minutes per kernel on average. Compared to common methods, that’s roughly a 24x speedup in kernel generation time!
Combined forward and backward: yasp’s LLM agent achieves nearly 100% correctness for combined forward and backward kernel generation at an incredibly high speed. Our agent is not only able to generate numerically correct kernels for both passes, but does this at a pace dramatically outperforming existing methods.
Our experiments were conducted on a workstation with an Intel® Core™ i9-14900K CPU and an NVIDIA RTX 4090 GPU. With CUDA kernel compilation primarily relying on the CPU, and runtime evaluation running on the GPU, both contribute to the reported times.
Why LLM-based kernel generation is a game-changer
What does this all mean for you? Fast kernel generation enables you to create specialized CUDA kernels on-the-fly, rather than waiting days or even weeks for hand-written implementations.
Quick warm-up: The model compiles quickly and is ready for training in no time.
Tailored performance: yasp generates kernels precisely tailored to your specific deep neural network (DNN) architecture, input size, and underlying GPU hardware. This leads to significant speedups compared to standard libraries like cuBLAS or cuDNN.
Optimal efficiency: Rapid kernel generation allows for multiple iterations, empowering you to discover the most efficient kernel implementations for any given workload.
The future of deep learning training is NOW
We're not merely compiling code. Instead, yasp is intelligently crafting it, empowering AI researchers and developers to reclaim their time and focus on what truly matters: groundbreaking innovation. By automating the most intricate parts of kernel generation, we remove a significant hurdle, allowing for faster experimentation, more efficient training, and ultimately, accelerating the next wave of AI breakthroughs.
Book a demo with our specialists to discover how yasp can transform your development process today!